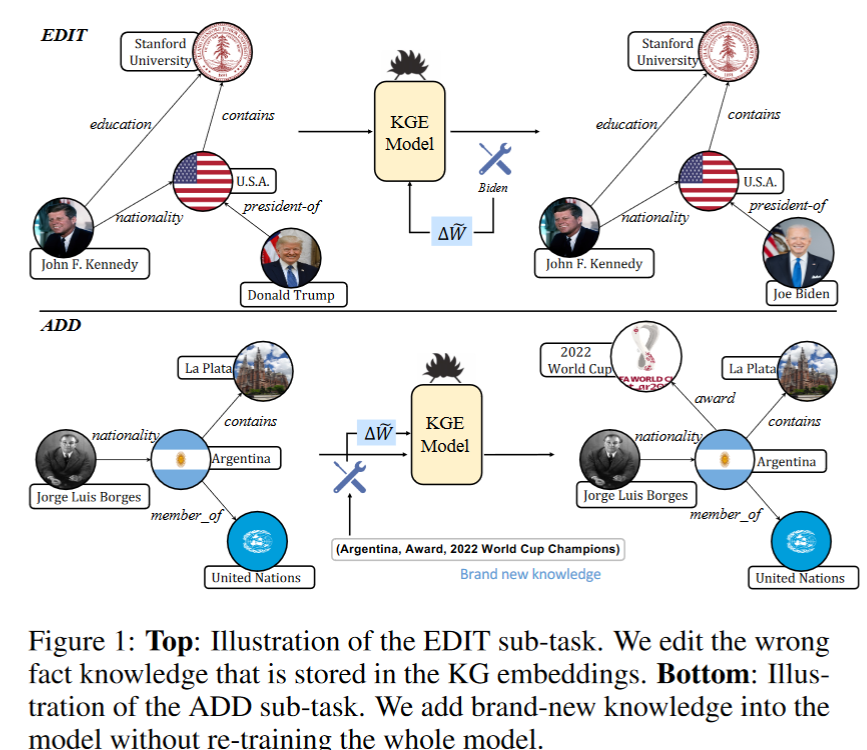
PyG Graph sage 源码分析
PyG Graph sage 源码分析
- Neighbor sampler
NeighborSampler!
1 | NeighborSampler(data, size, num_hops, batch_size=1, shuffle=False, drop_last=False, bipartite=True, add_self_loops=False, flow='source_to_target') |
该方法返回一个生成器,主要需要的参数有data数据、采样邻居数(或比例)、采样跳数、bs等。其中bipartite参数指定返回的数据形式:
- bipartite=True 返回DataFlow 数据形式
- bipartite=False 返回Data 数据形式(实际上是Data形式的subgraph)
在 https://github.com/rusty1s/pytorch_geometric/blob/a8f32aaff8608e497f112f700d1fd8ca0cb9ae18/test/data/test_sampler.py 中我们可以看到两种方法的使用例子。
- bipartite
1 | Neighborloader = NeighborSampler(Cora[0], size=[25, 10], num_hops=2, batch_size=1, |
即 layer 0有9个点,layer 1有4个点,layer 2有1个点(目标)
hoop设置两跳,ner里于是有了两个Block数据:、
ner[0], ner[1]
# 输出: Block(n_id=[9], res_n_id=[4], e_id=None, edge_index=[2, 18], size=[2]),
# Block(n_id=[4], res_n_id=[1], e_id=None, edge_index=[2, 4], size=[2]))
- n_id是二分图中节点(从0开始)到原图的id映射
- res_n_id是二分图中向其他层连接的节点id
- edge_index二分图中的边
具体来看:
1 | ner[0].n_id, ner[0].res_n_id |
也就是说这一层ner[0] 26个节点编号:[ 109, 2481, 234, 826, 2287, 114, 2506, 610, 2288]
其中第[5, 8, 7, 6](即[ 114, 2288, 610, 2506])是和下一层ner[1] 相连接的:
1 | ner[1].n_id, ner[1].res_n_id |
batch>1时也就是采样一个包含batch个目标点的二分图。
因此我们在训练时要先输入layer 0进行训练,然后再此基础上对layer 1进行训练,最终得到layer 1的res_n_id的输出。1
2
3
4
5
6
7
8
9
10def forward_data_flow(self, x, edge_weight, data_flow):
block = data_flow[0]
weight = None if block.e_id is None else edge_weight[block.e_id]
x = relu(
self.conv1((x, None), block.edge_index, weight, block.size))
block = data_flow[1]
weight = None if block.e_id is None else edge_weight[block.e_id]
x = relu(
self.conv2((x, None), block.edge_index, weight, block.size))
return x
- subgraph
subgraph模型上与不使用NeighborSampler的无异,唯一区别是Data中的变量:1
2
3
4
5
6
7ner[1].n_id, ner[1].res_n_id
\# 输出:Data(b_id=[1], e_id=[20], edge_index=[2, 20], n_id=[19], sub_b_id=[1])
ner.b_id, ner.sub_b_id, ner.n_id
\# 输出:(tensor([100]),
tensor([18]),
tensor([ 95, 2073, 2054, 6, 2074, 2072, 315, 2576, 1416, 734, 2311, 1628,
1841, 1680, 408, 2056, 1602, 1204, 100]))
- n_id是子图中节点(从0开始)到原图的id映射
- b_id是目标点
- sub_b_id是子图中目标点的id
batch>1时也就是采样一个包含batch个目标点的子图。
我们在训练时放入采样的子图,只取目标点sub_b_id作为模型输出即可,其他不变。1
2out = model(data.x[subdata.n_id], subdata.edge_index, weight)
out = out[subdata.sub_b_id]
来自 https://zhuanlan.zhihu.com/p/113862170
- 在使用过程中,逐层输入block的node和index,通过聚合函数,会自动把输出的层聚合成下一个hop的node数量,
- TODO:neighbor sampler的分析,到时候motif sampler要用