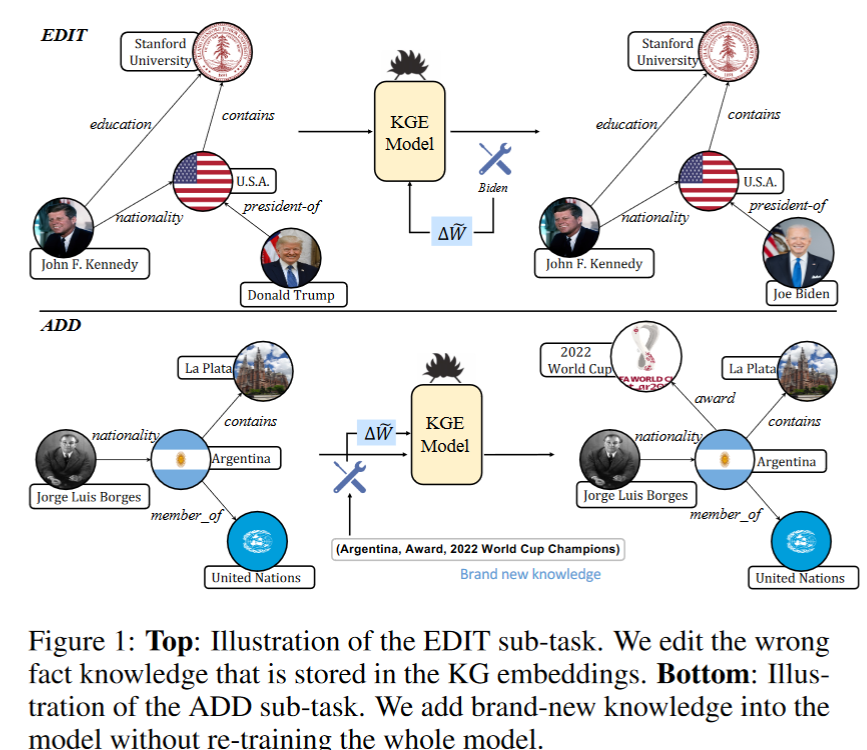
Incorporating Structured Sentences with Time-enhanced BERT for Fully-inductive Temporal Relation Prediction
Motivations
- Traditional embedding-based TKGC models (TKGE) rely on structured connections cannot handle unseen entities.
- Symbolic rule methods suffer from inflexibility of symbolic logic.
- PLMs are pre-trained in large-scale corpora, so they are not adapted to particular domains and cannot handle temporally-scoped facts.
Previous works
TLogic utilizes temporal random walks to get temporal logical rules in symbolic form. When TLogic applies the found rules to answer questions, it must precisely match each relation and timestamp in the rules, including relation types, relation order and time order. If there are no matching body groundings in the graph, then no answers will be predicted for the given questions.
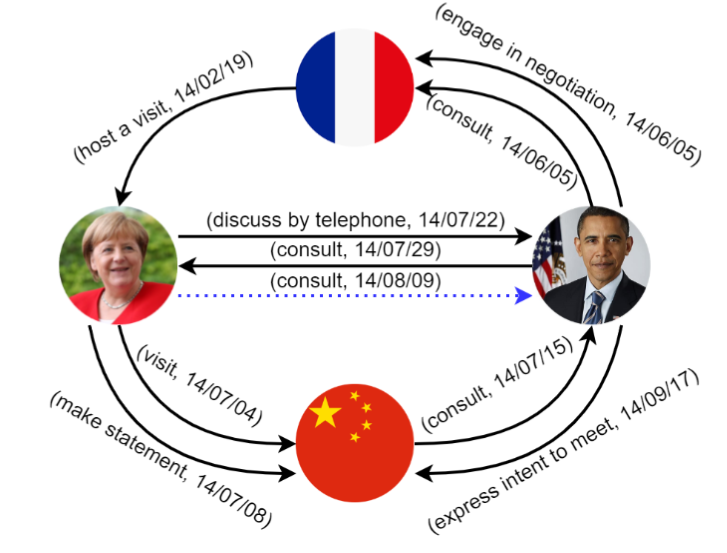
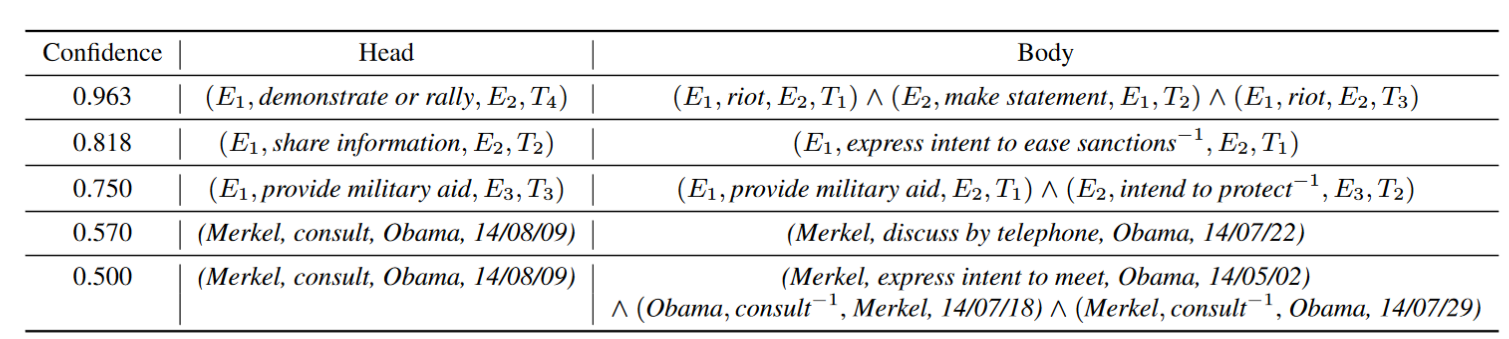
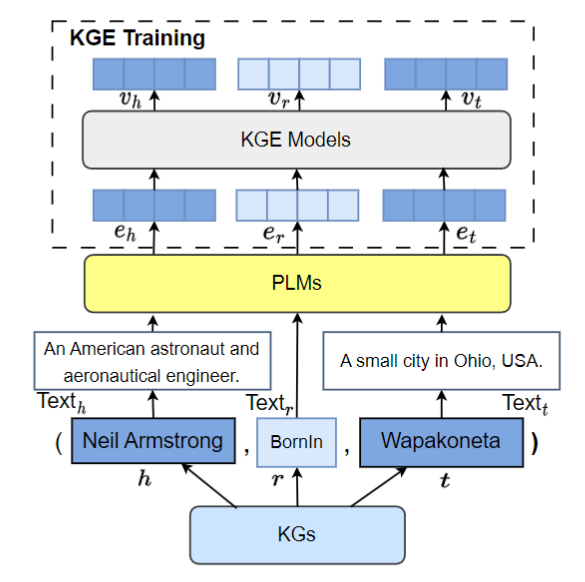
Previous PLMs are treated as a simple text encoder to incorporate text information, which ignores the structure information.
Contributions
- Propose SST-BERT, a model that incorporates Structured Sentences (constructed from relation paths and historical descriptions) with Time-enhanced BERT
- The structured sentences enable SST-BERT to learn in semantic space, overcoming the symbolic restrictions in TLogic.
- Propose a pre-training task that involves time masking to enable SST-BERT to focus on time-sensitive facts.
Methods
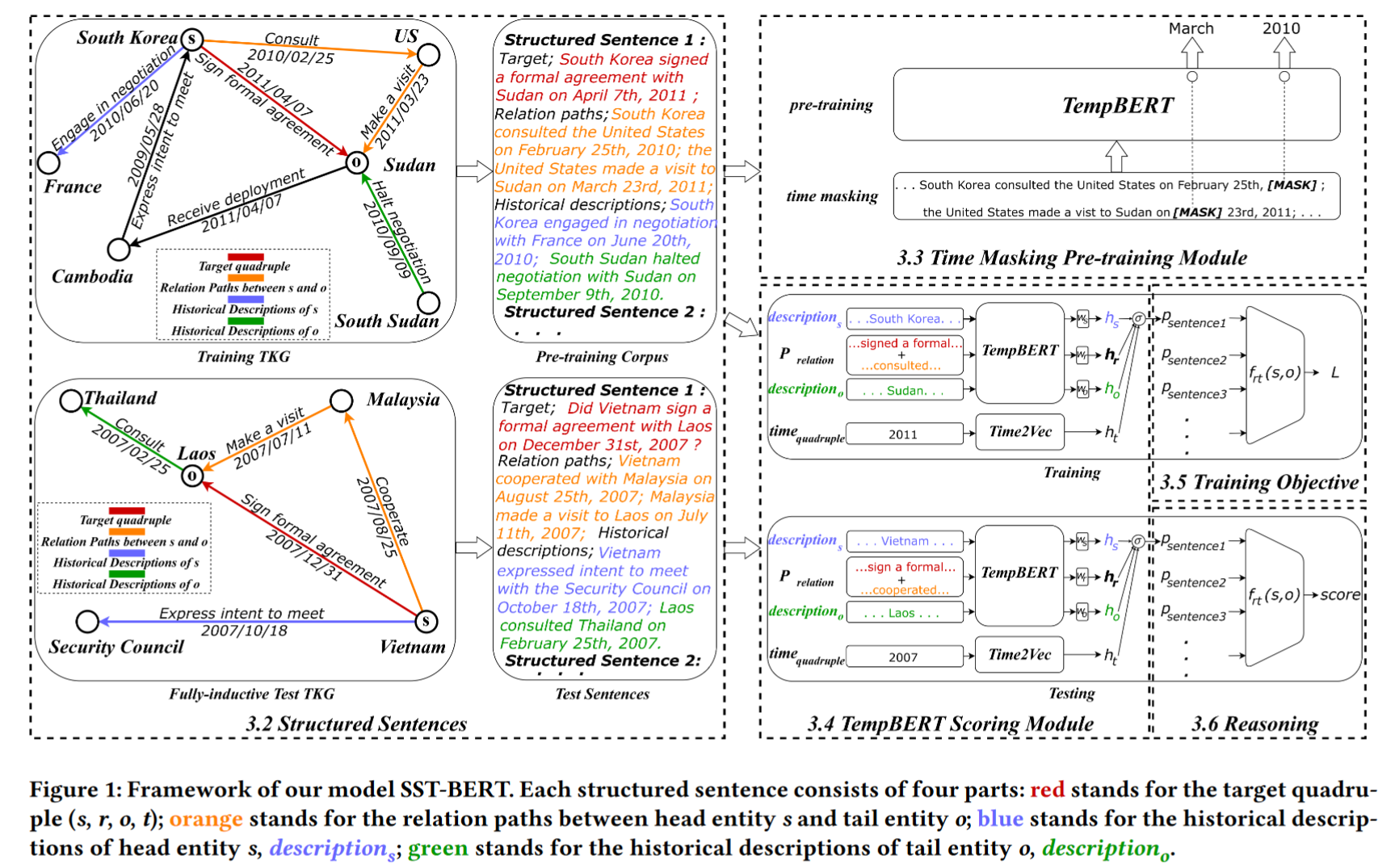
Structured sentences
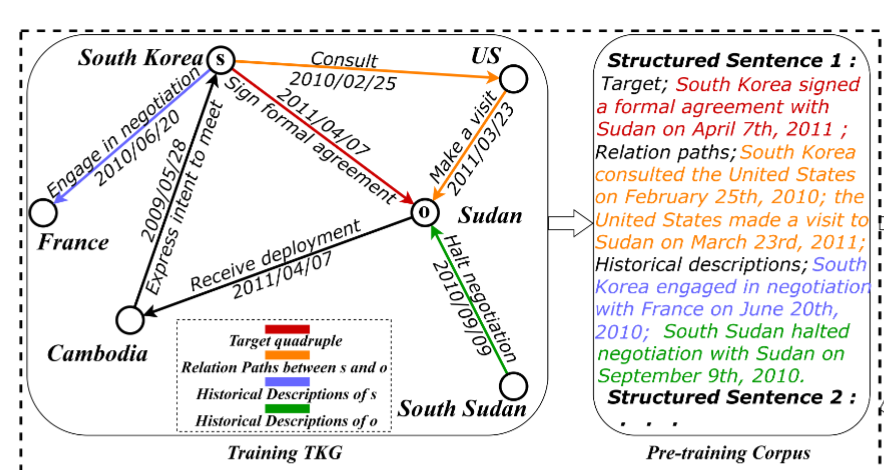
They convert symbolic edges into natural language sentences and capture the semantic logic hidden behind the relation paths.
Limitations: need to define a prompt template for each relation type.
They argue that the old facts in the perspective of time offer vital background information for the target quadruples
They randomly select one edge which is not included in the relation paths as an old fact and regard it as a historical description to reflect the evolution of facts.
Usually, these historical descriptions are semantically relevant to target quadruples and act as rich historical knowledge related to target entities. Furthermore, in the fully-inductive setting, the degrees of most entities are small, which means the ideal paths connecting target entities are limited and result in little information
Time Masking Pre-training Module
PLMs are pre-trained in noisy and generally purposed opendomain corpora, so PLMs are not effective for applications on timespecific downstream tasks
Construct pre-training corpus using structured sentences extracted from all training quadruples.
Because each edge in the training TKGs is considered positive, all the generated sentences for it can be regarded as logically supporting the establishment of the edge to some extent.
Time-masking pre-training
They focus on the time tokens, and 25% of the temporal expressions in $T$ are randomly sampled.

TempBert Scoring Module
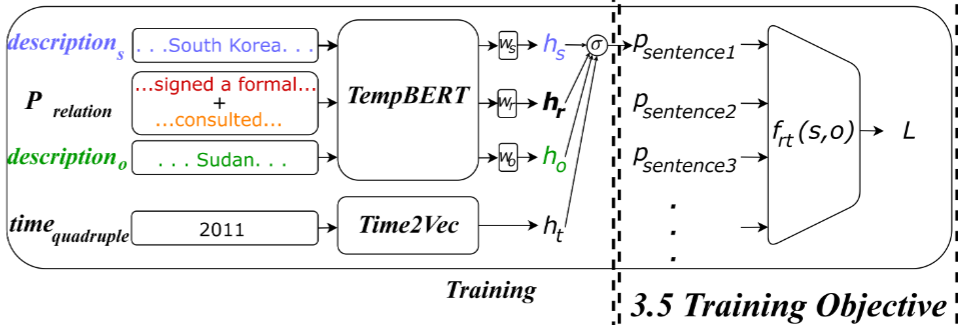
Use embedding at [CLS] generated by PLMs as entity/relation representations.
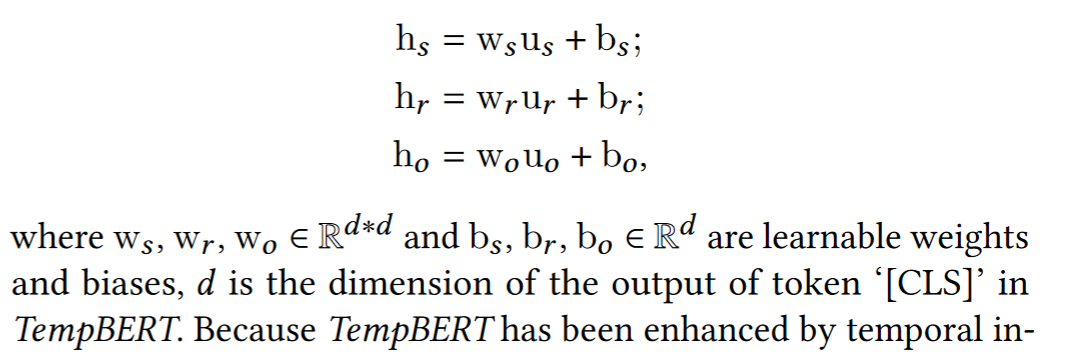
Time-encoding
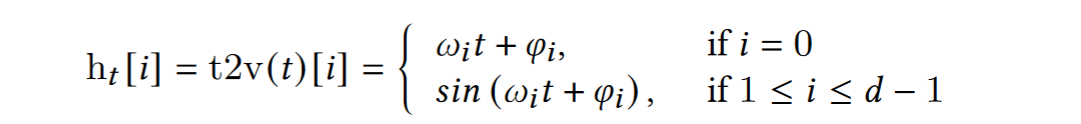
Score functions
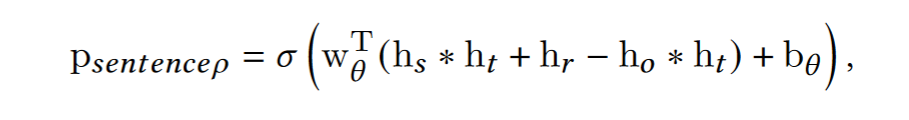
Training Objects

For each quadruple, we can have $N$ sentences, which denotes $N$ predictions. Weight them by timestamps.

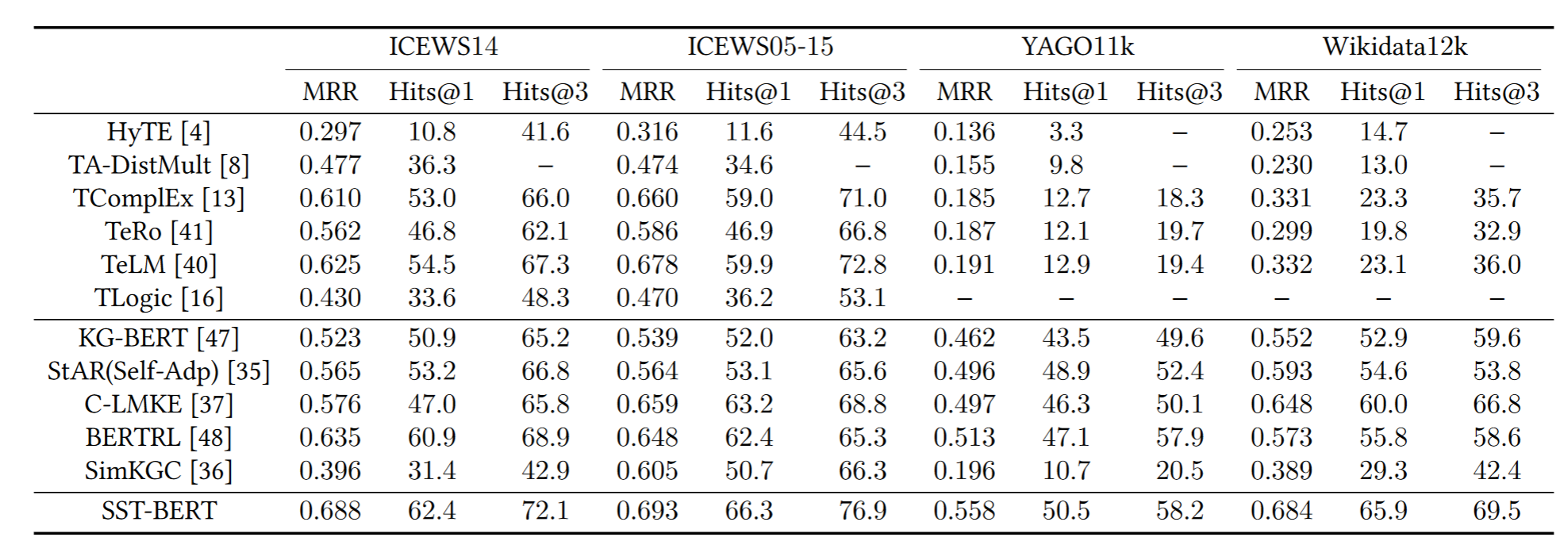
Experiments
Transductive
 Inductive
Inductive
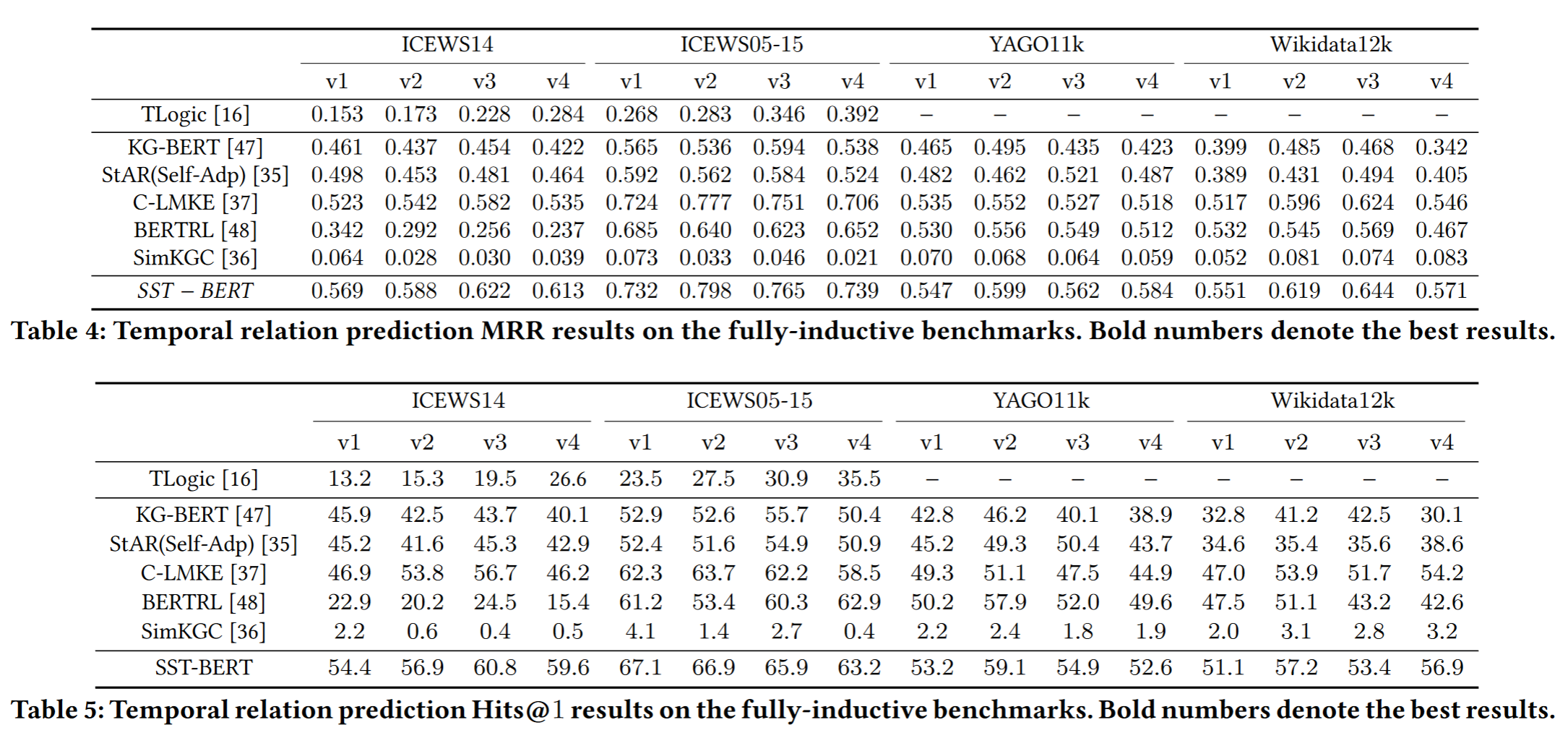 Explainability
Explainability
Problems
Information leakage in the pretrained PLMs?