Neural Graph Collaborative Filtering
Abstract:传统的深度学习协同过滤,ID的嵌入是直接输入交互层,但是在NGCF中,其能捕获用户和物品之间的高阶关系。 Method:假设:Intuitively, the interacted items provide direct evidence on a user’s preference [16, 38]; analogously, the users that consume an item can be treated as the item’s features and used to measure the collaborative similarity of two items. Message Construction:$e_i$,$e_u$ 做哈达玛积,然后通过$W_2$ 转换,然后和$e_1$ 通过$W_1$ 做转换之后相加。然后除以度数乘积进行归一化。 Message Aggregation:邻居信息相加聚合在加到用户自身上和用户相加通过激活函数。 多层次卷积:很典型的图卷积矩阵定义 Model prediction:每一层都会得到用户...

torch.einsum 实现CIN
研究了一下如何用pytorch实现CIN的操作。 CIN的数学原理假设总共有$m$个field,每个field的embedding是一个$D$维向量。 压缩交互网络(Compressed Interaction Network, 简称CIN)隐向量是一个单元对象,因此我们将输入的原特征和神经网络中的隐层都分别组织成一个矩阵,记为$X_0$和$Xk$,CIN中每一层的神经元都是根据前一层的隐层以及原特征向量推算而来,其计算公式如下: X^k_{h,*}=\sum ^{H_{k-1}}_{i=1}\sum ^{m}_{j=1}W^{k,h}_{ij}(X^{k-1}_{i,*}\circ X^{0}_{j,*})其中,第k层隐层含有$H_k$条神经元向量。$\circ$是Hadamard product,即element-wise product,即,$ \left \langle a_1,a_2,a_3\right \rangle\circ \left \langle b_1,b_2,b_3\right \rangle=\left \langle a_1b_1,a_2b_2,a_...
neo4j导入和创建多数据库
前言最近在玩neo4j,用来存储实验的图数据库,以前都是只用做一个数据库就好了。但是由于一个数据集的paper被review怼的惨不忍睹,只能多搞几个数据集来实验,于是就开始倒腾建立多个数据集的方法。 Neo4j-admin import使用Neio4j-admin import导入csv neo4j-admin --database=xxx.db --nodes=users.csv --relationships=relations.csv —database:数据库名字,由于创建了多个数据库所以必须改名,如果出现数据库名字重复或者不为空可以执行sudo rm -rf /var/lib/neo4j/data/databases/xx.db清空 —nodes:节点csv,[name:ID],ID字段是必须的,是唯一索引,name是feature的名字,:LABEL是节点的标签,貌似可以用[name:ID(label)]替代:LABEL ,但是此时在import 的时候要在--nodes:User=users.csv明确label 123456movies.csv. movieId...
PyG Graph sage 源码分析
PyG Graph sage 源码分析 Neighbor sampler NeighborSampler! 1NeighborSampler(data, size, num_hops, batch_size=1, shuffle=False, drop_last=False, bipartite=True, add_self_loops=False, flow='source_to_target') 该方法返回一个生成器,主要需要的参数有data数据、采样邻居数(或比例)、采样跳数、bs等。其中bipartite参数指定返回的数据形式: bipartite=True 返回DataFlow 数据形式 bipartite=False 返回Data 数据形式(实际上是Data形式的subgraph) 在 https://github.com/rusty1s/pytorch_geometric/blob/a8f32aaff8608e497f112f700d1fd8ca0cb9ae18/test/data/test_sampler.py 中我们可以...
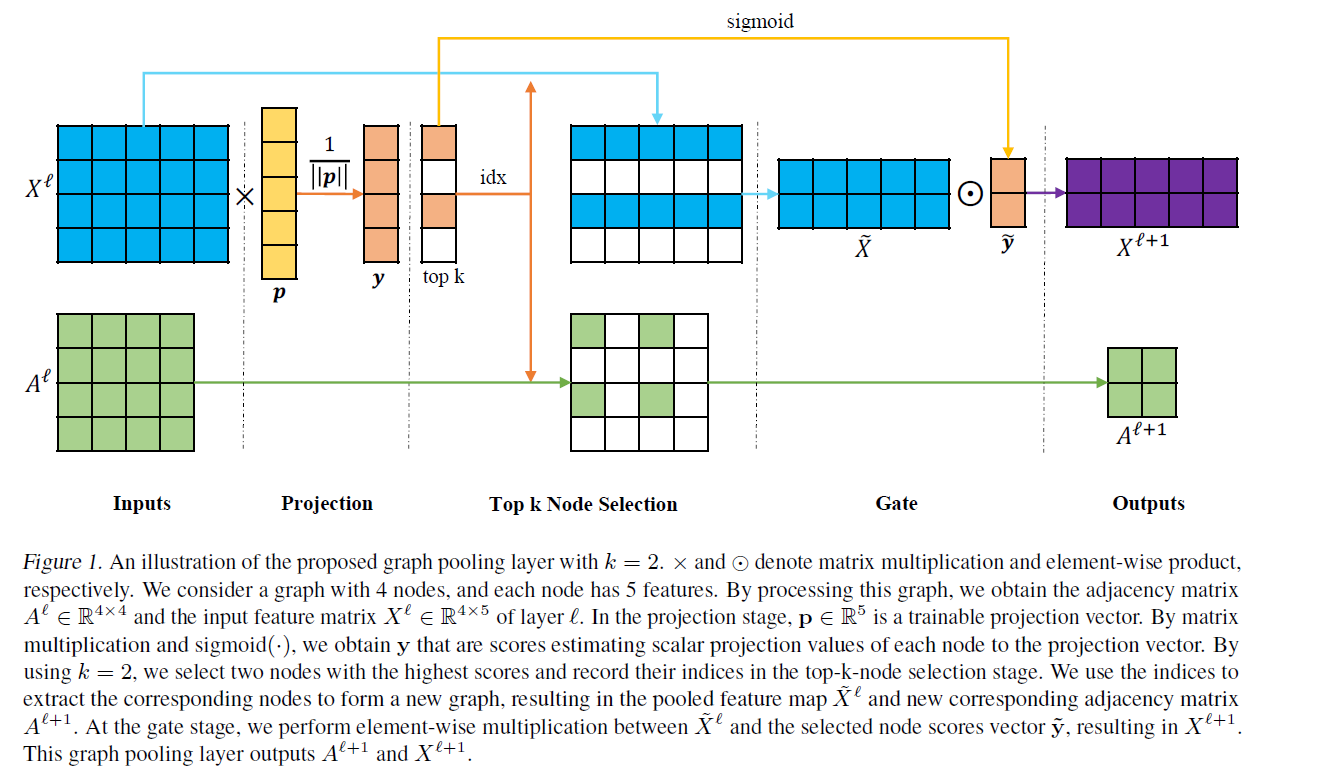
Graph U-Nets
简介:在传统图像领域,encoder-decoder结构,比如U-nets已经在许多图像像素领域有着许多成功的应用。然而在图像领域,由于池化和反池化操作在图领域的实现并没有自然的实现,导致这样的结构并没有在图网络中应用。本文提出了一种在图结构上池化和反池化的操作,池化层可以根据节点在可训练投影向量上的标量投影值,自适应地选择节点,形成较小的图。反池化层可以把池化层生成的数据恢复成带位置信息的原始结构。 Graph Pooling Layer:图池化,首先有节点特征X,邻接矩阵A,通过一个P向量来训练节点之间的位置关系,然后通过SIGMOD(y)+TOP-K来提取top-K特征,提取完之后,保存idex,从X,A提取特征和邻接矩阵。 Graph Unpooling Layer:学习distribution,把pool过之后的KC矩阵,和选定的节点idx,恢复成原始的NC矩阵。 只把选定位置的点设为kC的特征,NC的其他位置设为0
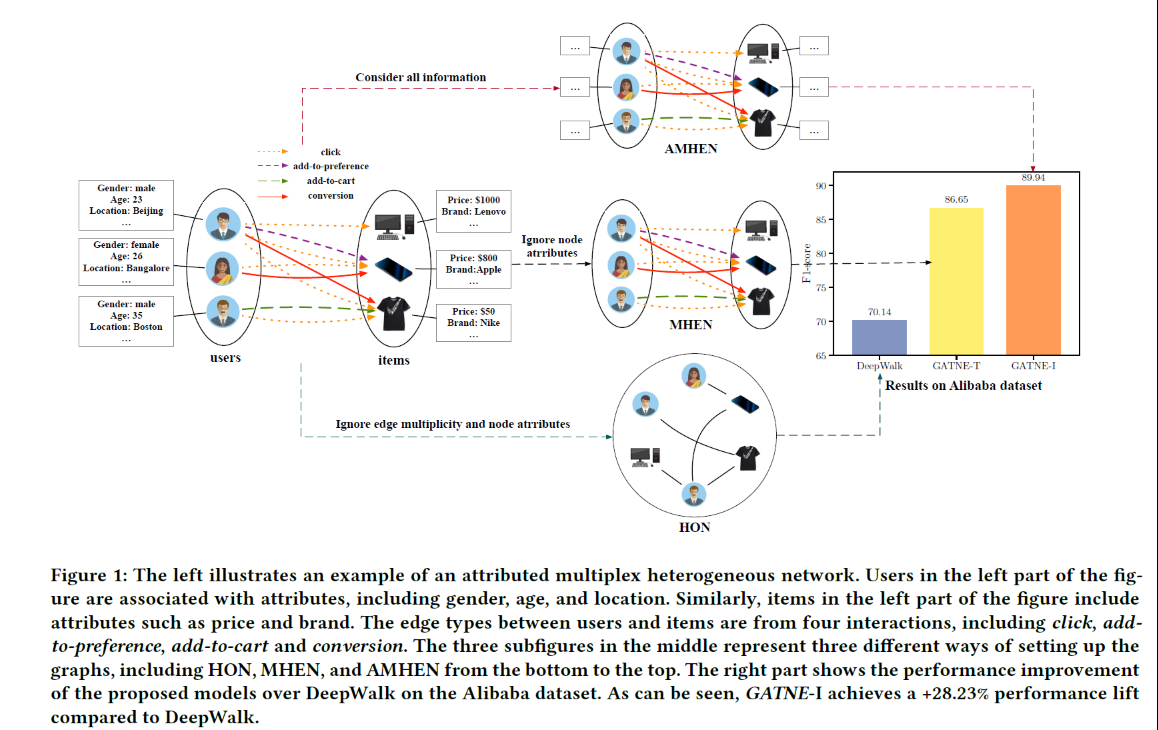
Representation Learning for Attributed Multiplex Heterogeneous Network
简介:现有的方法主要专注于具有单一类型节点/边缘的网络,并且不能灵活处理大型网络。许多真实世界的网络包括数十亿个节点和多种类型的边,每个节点与不同的属性相关联。本文提出了一种带属性多通道异构图网络,本网路结构可以支持transductive和indective的学习。 相关工作: Transductive Model: GATNE-T:此处,模型通过边的种类,学习节点在不同边聚类下的表达。采用的是graph sage的聚集方法。 然后把节点的所有边种类信息拼接起来,然后用self-attention进行聚合。 Inductive Model: GATNE-I:为了解决一些节点之间边不存在的问题,通过节点的属性和节点的种类来对节点进行嵌入。 Meta-Random-walk:对不同种类的边进行不同的游走,然后用负采样进行训练,最后用于节点预测。

newstart
开始一个新的生活吧
最新文章