Redundancy-Free Computation for Graph Neural Networks
Redundancy-Free Computation for Graph Neural Networks
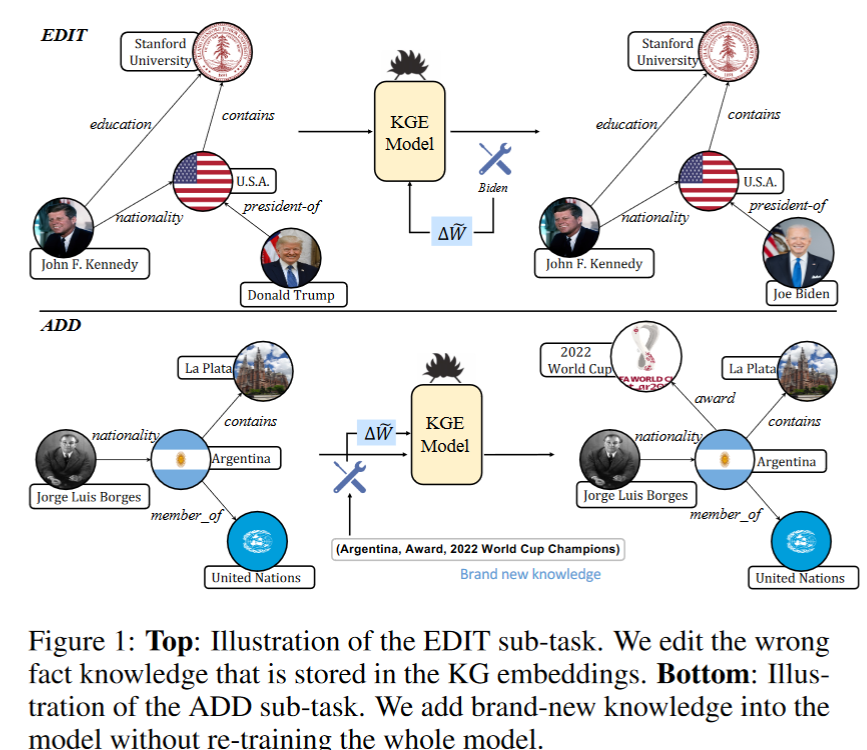
Motivation
To avoid redundant computations:减少冗余计算
HAGs are functionally equivalent to standard GNN-graphs:性能不变
An agnostic method:对所有模型都适用
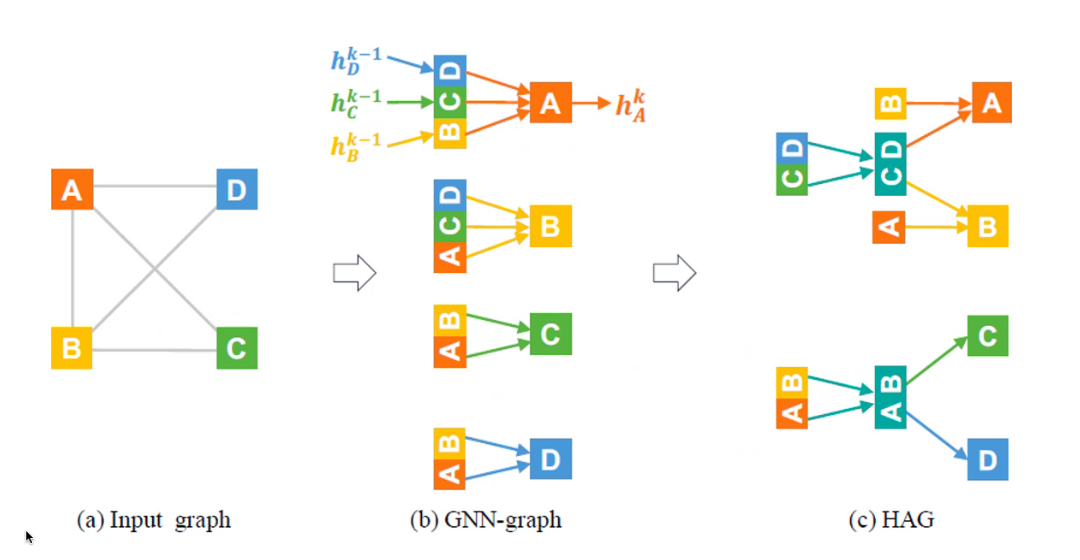
对邻居上重合的的vector进行聚合,然后再传递。
HAGs
把聚合的点和原来的点聚合,生成一张新图
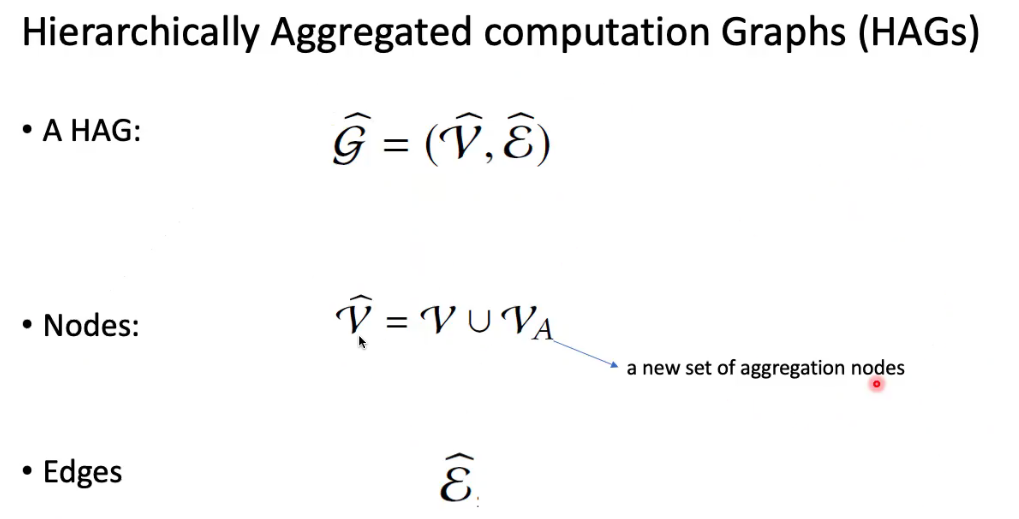
Existing GNNs
- 没有顺序:GCN
- 有顺序:LSTM聚合
Aggregation Nodes

如果是原图的属性,就用节点的隐藏向量
如果是聚合节点,就用聚合向量。
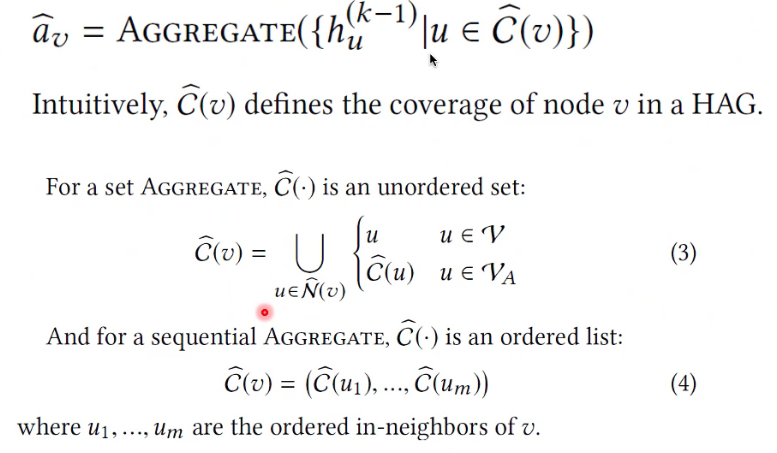
Cost Function

Algorithm

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 RMan's Blog!
相关推荐
2020-11-13
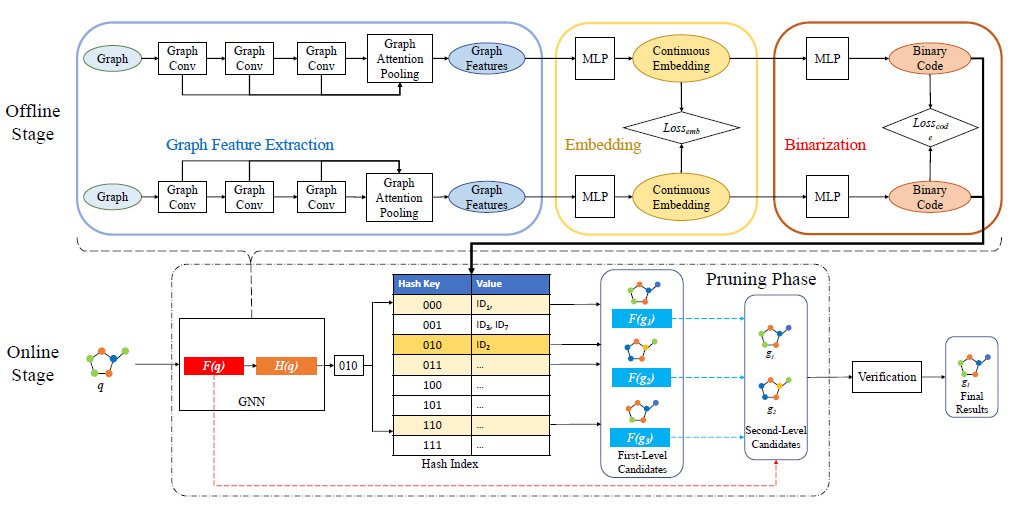
GHashing Semantic Graph Hashing for Approximate Similarity Search in Graph Databases
Objection: Retrieve graphs from the database similar enough to a query. Optimize the pruning stage. Background: Graph Edit Distance (GED) is a method to measure the distance between two graphs. The current similarity search, first compute the lower bound between the query and the every candidate graph and they prune the graph larger tan than the threshold. Then, they compute the exact GED in the remaining graphs. Challenges: The computation of Graph Edit Distance (GED) is NP-hard. Exis...
2020-05-05
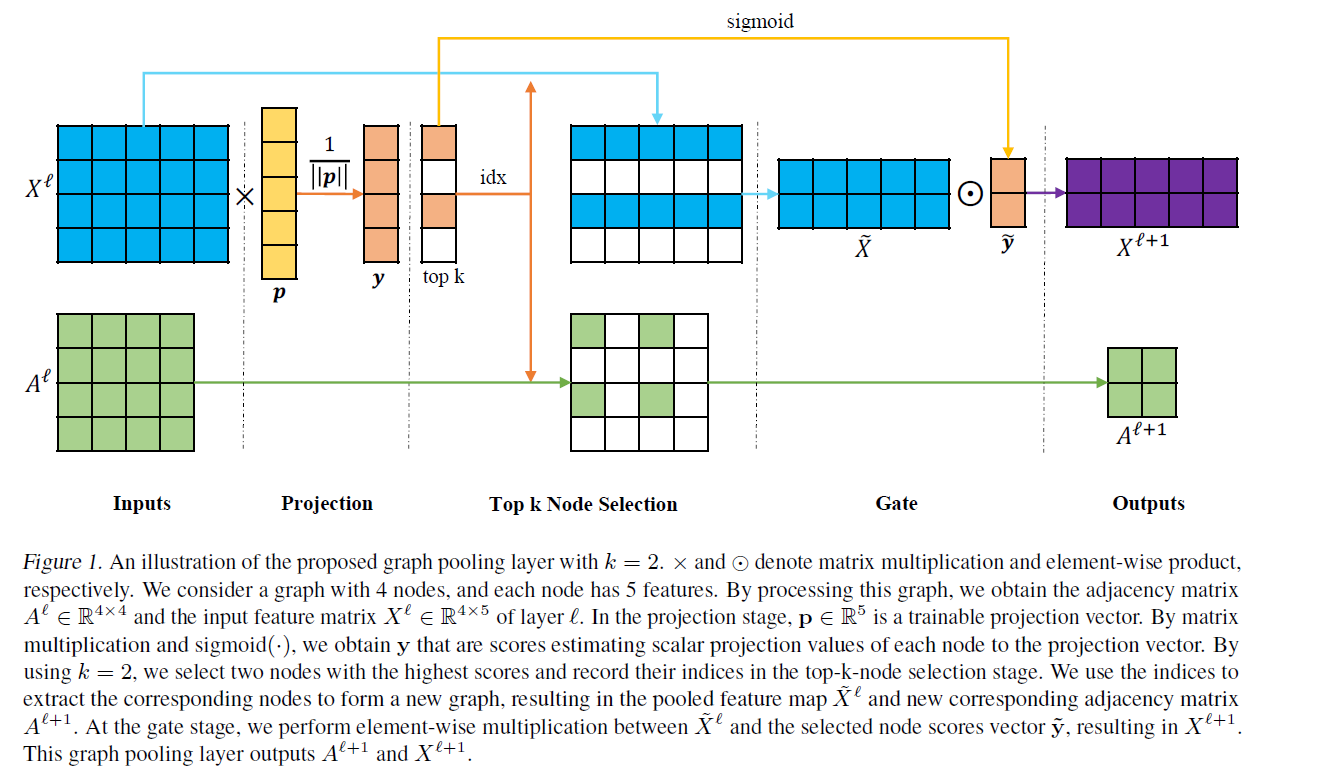
Graph U-Nets
简介:在传统图像领域,encoder-decoder结构,比如U-nets已经在许多图像像素领域有着许多成功的应用。然而在图像领域,由于池化和反池化操作在图领域的实现并没有自然的实现,导致这样的结构并没有在图网络中应用。本文提出了一种在图结构上池化和反池化的操作,池化层可以根据节点在可训练投影向量上的标量投影值,自适应地选择节点,形成较小的图。反池化层可以把池化层生成的数据恢复成带位置信息的原始结构。 Graph Pooling Layer:图池化,首先有节点特征X,邻接矩阵A,通过一个P向量来训练节点之间的位置关系,然后通过SIGMOD(y)+TOP-K来提取top-K特征,提取完之后,保存idex,从X,A提取特征和邻接矩阵。 Graph Unpooling Layer:学习distribution,把pool过之后的KC矩阵,和选定的节点idx,恢复成原始的NC矩阵。 只把选定位置的点设为kC的特征,NC的其他位置设为0
2020-05-20
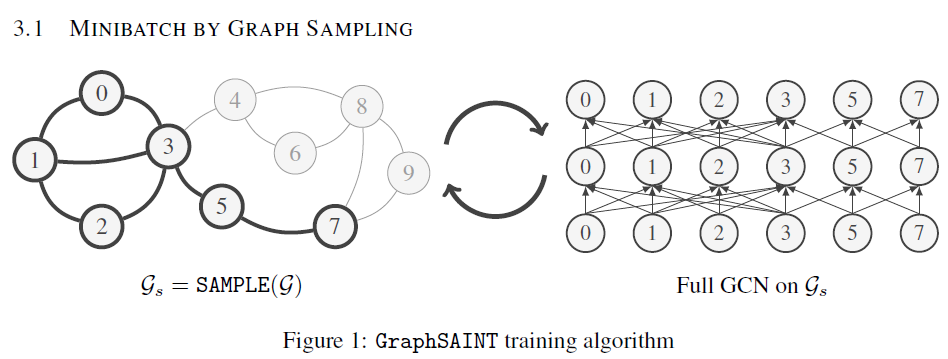
GraphSAINT,一种无偏的图采样方法
背景在现在的图卷积中,由于图的大小可能非常大,传统的在全图上进行图卷积的操作往往是不现实的。因此往往采用了图采样的方法。图采样大致会分为:Layer Sampling 和 Graph Sampling两种。但是这两种方法都存在着一些问题。 Layer Sampling: 1. 邻居爆炸:在矩阵采样多层时,假设每层采样n个邻居,则会导致$n^2$级别的节点扩充速度。 2. 领接矩阵稀疏:在矩阵采样的过程中,会导致邻接矩阵稀疏化,丢失一些本来存在的边。 3. 时间耗费高:每一层卷积都要采样,这就导致计算的时间耗费。 Graph Sampling: Graph Sampling是一种相对好的采样方法,可以在preprocess阶段提前采样图,并且可以进行mini batch的加速。但是这样的采样往往会丢失一些信息。 本文为了解决以上问题,提出了一种在图上进行Graph Sampling的相对较好的方法。 方法在普通的Layer采样过程中,我们希望采样之后产生的偏差最小。这个偏差可以由如下的公式得出。 我们希望如下的偏差最小,经过一系列复制的推导,在$P_e$等于如下值的时候,偏...
2021-10-13
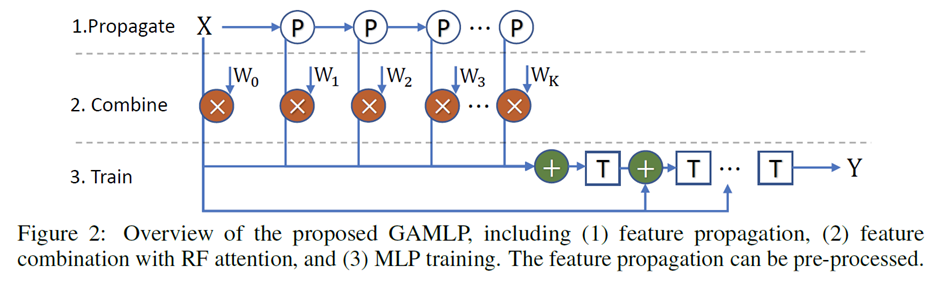
Graph Attention Multi-Layer Perceptron
Motivation The size of the K-hop neighbors grows exponentially to the number of GNN layers (High Memory Cost). GNN has to read great amount of data of neighboring nodes to compute the single target node representation, leading to high communication cost in a distributed environment (High Communication Cost). GNN的每一次特征传播都需要拉取邻居特征,对于k层的GNN来说,每个节点需要拉取的k跳以内邻居节点特征随着层数增加以指数增加,会占用大量内存。对于稠密的连通图,每个节点在每次训练的时候几乎需要拉取全图的节点信息,造成海量的通信开销。 A commonly used approach to tackle the issues is sampling. The s...

2021-06-17
Breaking the Limits of Message Passing Graph Neural Networks
Motivation Existing GNNs’ expressive power is limited to 1-WL test, thus they cannot count some substructures likes: triangle, tailed triangle, and 4-cycle graphlets Existing beyond 1-WL test GNNs is computational heavily $O(n^3)$ and memory hungry $O(n^2)$. Some methods introduce some handcrafted features that cannot be extracted by GNN into the node attributes to increase the GNN’s expressive power: Distance encoding, identity GNN, and some Jure’s works. Existing GNN focuses on the lo...
2020-05-19
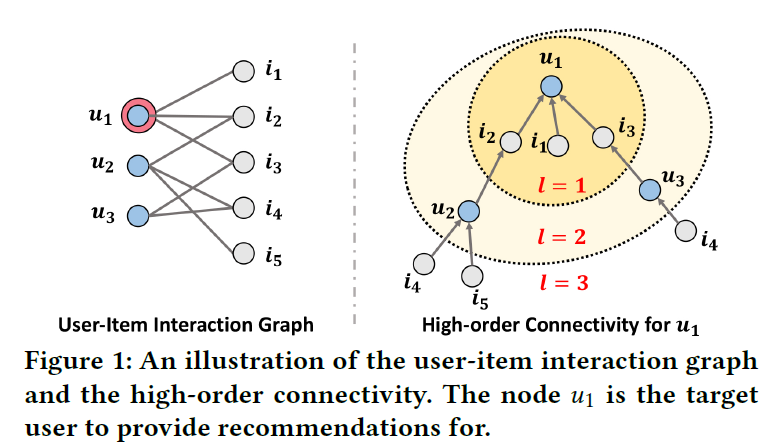
Neural Graph Collaborative Filtering
Abstract:传统的深度学习协同过滤,ID的嵌入是直接输入交互层,但是在NGCF中,其能捕获用户和物品之间的高阶关系。 Method:假设:Intuitively, the interacted items provide direct evidence on a user’s preference [16, 38]; analogously, the users that consume an item can be treated as the item’s features and used to measure the collaborative similarity of two items. Message Construction:$e_i$,$e_u$ 做哈达玛积,然后通过$W_2$ 转换,然后和$e_1$ 通过$W_1$ 做转换之后相加。然后除以度数乘积进行归一化。 Message Aggregation:邻居信息相加聚合在加到用户自身上和用户相加通过激活函数。 多层次卷积:很典型的图卷积矩阵定义 Model prediction:每一层都会得到用户...
最新文章